Each summer, Man AHL welcomes research interns who work on specific projects for three months. Interns who have completed graduate degrees focus on individual projects, while those completing undergraduate degrees form a team. This summer, Saanya Verma (first year undergraduate, Mathematics, University of Cambridge), Abdul Ahad Hasan (final year undergraduate, Mathematics, University of Cambridge), Andrei Braguta (first year postgraduate, Computing, Imperial College London), and Bella Henderson (second year undergraduate, Mathematics, University College London) worked together on three team projects, one of which was focused on using ChatGPT for targeted sentiment analysis. Some of their findings are summarised in this article.
Introduction
Since its release in November 2022, ChatGPT has taken the world by storm. With around 175 billion parameters and a training set of approximately 570 GB of text data[1], ChatGPT 3.5’s capabilities are extensive. GPT-4, the most recent version at the time of writing, is even bigger and stronger.[2] Both versions are highly accessible and can be applied to a broad range of language tasks, from writing poetry to summarising text.
But how does ChatGPT fare in finance? In this paper, we investigate its ability to conduct financial sentiment analysis: the process of analysing financial text (such as earnings call transcripts) to determine whether the tone it conveys is positive, negative or neutral. We evaluate its ability using a range of prompting techniques and compare it to baseline word-counting methods.[3][4]
The Evolution of Sentiment Analysis Models in Finance
Sentiment analysis is among the main methods applied to text-based data in finance, with targeted sentiment analysis often used for more specialised problems. Targeted sentiment analysis assesses the sentiment of a statement with respect to a particular aspect of interest. Take the statement, ‘assets under management increased, but our profits decreased’, for example. The overall sentiment of the statement may be classified as neutral or even negative. However, if we are specifically interested in understanding the sentiment towards ‘assets under management’, targeted sentiment analysis would conclude the sentence is positive, whereas targeted sentiment towards ‘profit’ would be negative.
A classic baseline used in the academic finance literature for sentiment analysis is the family of dictionary-based methods, which map specific words to assigned sentiment: for example, ‘improve’ may be considered a positive word. In 2007, one of the first examples of this technique was introduced by Paul Tetlock. In his paper[5], he uses a psychosocial dictionary of words, together with their assigned polarity, to analyse news articles and consequently make market predictions based on word counts for each sentiment category
These deceptively simple training tasks, in allowing the models to learn patterns across a broad range of text data, have been shown to enable them to capture, compress, and internalise human knowledge.
Since then, more accurate and specialised dictionaries have been produced specifically for finance. The Loughran McDonald (LM) dictionary[6], released in 2010, is an extremely popular sentiment lexicon of words tailored for financial contexts, including 85,131 different words (2355 negative, 354 positive, 82,422 neutral) from ‘AARDVARK’ to ‘ZYMURGY’. The advantage this has over psychosocial dictionaries is that neutral finance-specific words that would carry sentiment outside of finance, such as the word ‘liability’, are accounted for. For example, an accounting statement on liabilities would not be falsely assigned negative sentiment simply for containing the word ‘liability’.
More recently, Large Language Models (LLMs) have established themselves as ubiquitous building blocks for more complex text-based applications. These statistical models are typically trained on vast amounts of text to perform tasks such as predicting the next word in a sentence, filling gaps, or deciding which of two sentences is most likely to follow. These deceptively simple training tasks, in allowing the models to learn patterns across a broad range of text data, have been shown to enable them to capture, compress, and internalise human knowledge. Based on a branch of machine learning known as Deep Learning, under the hood, LLMs are designed as artificial neural networks with tens to hundreds of billions of parameters, with a large proportion of models using the Transformer neural architecture[7][8].LLMs have been around since the days of BERT[9], launched in 2018, but more recently have begun to show increasingly powerful capabilities as training data and model size have increased. Examples of well-known LLMs today include: LaMDA[10], PaLM[11] (Google), the GPT family[2] (OpenAI), Claude[12] (Antropic), Gopher and Chinchilla[13] (DeepMind), LLaMA[14] (Meta), and BloombergGPT[15] (Bloomberg).
A key driver behind ChatGPT’s success is its instruction following capabilities.
ChatGPT, a proprietary chatbot developed by OpenAI, is currently one of the most widely used LLMs. A key driver behind ChatGPT’s success is its instruction following capabilities[16]. Instruction following is built into the model by a process called Reinforcement Learning from Human Feedback (RLHF). This combines supervised fine-tuning, where the model learns from examples of human-created answers to questions (‘prompts’), with a reinforcement learning process, where the model receives feedback for its responses to prompts based on a reward model that itself is trained to follow human preferences. This RLHF process helps guide the model towards producing more helpful and safe responses. This has allowed ChatGPT to become very user-friendly: the user simply needs to feed in a natural language prompt and ChatGPT is generally able to provide appropriate responses across a diverse range of inputs.
Given its ease of use, both practitioners and academics have started to apply ChatGPT to tasks in finance, including sentiment analysis[17]. This made us curious – how would ChatGPT perform when tasked with targeted financial sentiment analysis? Would it outperform its equally simple finance-specific baseline, counting words from the LM dictionary?
Our Data
We work with a dataset of approximately 1000 sentences taken from earnings call transcripts, each labelled by a human annotator as having positive (p), negative (n) or neutral (i) sentiment with regards to a target, ‘margins’ (932 statements in total: 371 positive, 156 negative, 405 neutral). These statements are then used for prompt engineering, or designing an optimal prompt for ChatGPT. A separate set of approximately 1000 unseen labelled sentences is used as a final test set.
To illustrate, below are some examples from the training data:
- Sentence: “This seems to imply that you’re happy with the margin improvement at the expense of recruitment and volumes.”
Label: 'p'
- Sentence: “We shipped more products off of lower margin technology than we did higher margin technology.”
Label: 'n'
- Sentence: “Gross margin and fixed costs.”
Label: 'i'
Note that ‘margins’ is just an example target and these ideas should also apply to different targets.
Evaluating Performance
To analyse how LM and ChatGPT perform, we focus on a metric known as the F1- score.
To analyse how LM and ChatGPT perform, we focus on a metric known as the F1- score[18]. This metric balances both recall and precision across the three classes of ‘p’, ‘n’ and ‘i’ by taking a harmonic mean of the two. Recall tells us what fraction of the true positives (sentences the human annotator deemed to be in a class) the model captured, whereas precision tells us how likely it is for a sentence which the model has classified to actually be in the correct class. Taking this kind of properly constructed mean is particularly important when there is high class imbalance. F1-scores range from 0 to 1, with an F1 of 1 indicating perfect replication of human judgement.
Figure 1. F1-score: An Illustration
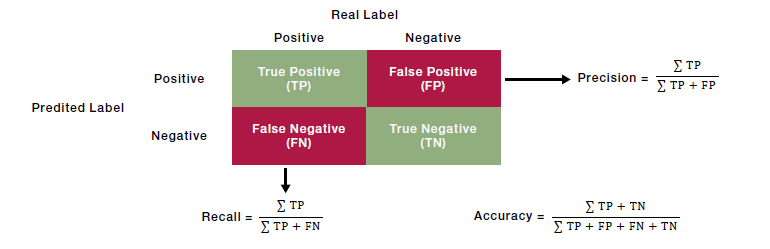
Source: MA, Jun & Ding, Yuexiong & Cheng, Jack & Tan, Yi & Gan, Vincent & Zhang, Jingcheng. (2019). Analyzing the Leading Causes of Traffic Fatalities Using XGBoost and Grid-Based Analysis: A City Management Perspective.
The Results
Loughran-McDonald Dictionary
Consistent with the literature, for the LM dictionary-based method, we simply count the occurrences of each word from the dictionary in the sentences from our dataset, assigning a score of +1 for positive words and -1 for negative words. Based on the sign of the summed sentiment score for each sentence, we then classify it as positive, negative, or neutral.
While ChatGPT can be easily used via user-generated prompts, it comes with its own nuances and drawbacks, as the prompt that the model is fed can heavily influence its response.
On our test set, this evaluation yielded an F1-score of 0.57.
If we focus in on some of the sentences which the dictionary method misclassifies, the limitations of even the best word-counting method become clear. First, only overall sentiment is considered, rather than targeted sentiment. As well as this, negation causes issues, with ‘not good’ being interpreted as positive by this method, simply due to the presence of the word ‘good’. Finally, evaluating each word individually fails to consider the context of the sentence. For example, ‘…high margin business to our company’ is classified as ‘i’ by the dictionary, since ‘high’ has no sentiment on its own and the model does not have the context that a ‘high margin’ is beneficial1. It is these long-range, contextual dependencies in natural language that more sophisticated models such as LLMs aim to capture more successfully than simple word-counting approaches.
ChatGPT
While ChatGPT can be easily used via user-generated prompts, it comes with its own nuances and drawbacks, as the prompt that the model is fed can heavily influence its response. Moreover, ChatGPT is known to frequently give plausible-sounding responses which are factually incorrect[19] (known as hallucination). To minimise this and to improve accuracy, it is important to study how different prompts affect prediction quality. This act of finding the optimal prompt is known as prompt engineering and is currently an area of active research[20][21][22].
Giving ChatGPT a persona is also known to potentially improve performance.
We investigate three of the most common methods for improving a prompt: few shot prompting, personas, and Chain of Thought (CoT) prompting. Zero-shot prompts refer to prompts that specify a task with no additional context, whereas few-shot prompts (also known as in-context learning) provide one or several illustrative examples within the prompt to help the model learn how to complete the task. Giving ChatGPT a persona is also known to potentially improve performance as it can help the model with sensitivity to jargon, nudging towards subject-specific knowledge. Meanwhile, CoT prompting[23] involves asking the model to explain the steps it follows when producing the answer, as well as potentially providing examples to illustrate this CoT reasoning. Deconstructing the output in this way can improve the model’s reasoning capabilities.
To effectively test ChatGPT’s targeted sentiment analysis abilities, we first establish an upper bound on the performance of ChatGPT. We asked the model to classify each statement from our dataset after explicitly giving it the sentiment it should output, using the prompt:
“Perform a sentiment analysis of the following statement, relating to margins and return ‘p’ if the sentiment expressed is positive, ‘n’ if it is negative, and ‘i’ if it is neutral:
[Statement A]
Here is an example:
The following sentence: [Statement A] should output [sentiment].
Make sure you output only one letter.”
This gave an F1 of 0.9, which acts as a rough upper limit to put the other F1- scores into context. It is notable that the upper limit is not 1.0: even if the answer is explicitly given to ChatGPT, a small proportion of the time it disagrees with the human annotator, highlighting how it does not necessarily ‘understand’ the prompt in a way a human might.2
Having established an upper bound, we begin with the following baseline prompt:
“What is the sentiment of this statement: [Statement], with regards to margins. Output ‘p’ if it has positive sentiment, ‘n’ if it has negative sentiment and ‘i’ if it is neutral.”
We found that adding only one example to the baseline prompt for either of the three classes causes the model to overclassify statements as that class.
We then incorporate ideas from the prompt engineering literature to see how they affect performance on the training data, before testing our top prompts on the test data. Note that our conclusions are specific to targeted sentiment analysis in this context, to our data, and to a certain model, and should not be generalised blindly. It would be interesting to study a broad range of models to understand the extent to which they respond positively or negatively to prompt engineering, or even different generations of ChatGPT.
We found that adding only one example to the baseline prompt for either of the three classes causes the model to overclassify statements as that class, suggesting it is possible to implicitly encode bias into ChatGPT’s outputs via the prompt (an effect also seen in the academic literature[23]). Adding examples for all three classes is more effective and slightly improves results on the training data, from an F1-score of 0.79 (with the baseline) to 0.8.
Providing the model with a persona reduces performance overall and produces the most variation in F1 score. For instance, when ChatGPT is asked to act as a random person, it vastly overclassifies statements as neutral, underperforming the LM dictionary method. This could possibly be explained by the fact that a person with little to no financial knowledge would likely classify statements as neutral unless they were obviously positive or negative. Conversely, given the persona of a financial investor, the model performs significantly better than the random person, although the financial investor persona causes it to overclassify statements as positive, indicating that ChatGPT associates some bullishness with the role. Again, we see this implicit bias that ChatGPT inherits from the prompt, highlighting the importance of well-engineered prompts to avoid unintended consequences.
Figure 2. Giving ChatGPT a Persona

Source: Man AHL.
While personas and chain-of-thought prompting are useful in gaining a baseline understanding of how the model might intuitively behave, neither of them improve performance significantly.
We then use a simple flavour of CoT prompting, asking ChatGPT to explain the reasoning for its classification decision. The query we use is:
“What is the sentiment of this statement: ____ with regards to margins. Output a single letter and nothing else: ‘p’ for positive sentiment, ‘n’ for negative sentiment and ‘i’ if the statement is neutral. Append an explanation of your reasoning onto the end of your output.”
We find, however, that this also reduces F1-score for our specific problem. It is possible that adding CoT worked examples, as is done in the original paper[24], may have produced better results. However, this could introduce bias, as described earlier.
Notably, while personas and CoT prompting are useful in gaining a baseline understanding of how the model might intuitively behave, neither of them improve performance significantly. We therefore consider more case-specific changes and combinations/modifications of these techniques.
After some experimentation with these techniques, we produced our best-performing prompt on the training set which gave an F1-score of 0.81 on the training data. This prompt includes providing three simple examples, reminding the model to only consider targeted sentiment, and asking it to output only one letter
“Perform a sentiment analysis of the following statement, relating to margins and return ‘p’ if the sentiment expressed is positive, ‘n’ if it is negative, and ‘i’ if it is neutral: ___. Limit your response to one letter and ensure you are only considering sentiment with regards to margins.”
Here are some examples:
- “Margins are going up” should return ‘p’.
- “Margins are going down” should return ‘n’.
- “I talked a little bit on margins” should return ‘i’.
The F1-score on the test set is still 0.81, whereas the baseline prompt achieves 0.74.
We experimented with various other ideas, which also did not prove to be helpful on the training set. These included asking ChatGPT for certainty before classifying a statement, asking for a numerical value to reflect positivity/negativity, and imposing different boundaries for the classes. We also looked at chaining prompts: querying the model with our best prompt, and then re-querying it with a different one based on whichever class it output, until consensus is reached. This latter scheme produced an F1-score of 0.82 on the training set, but failed to generalise particularly well and achieved 0.79 on our test set. These results further reinforce the idea that prompt engineering cannot be thought of as simply providing “intuitive” prompt modifications to improve output: for certain contexts like targeted sentiment analysis in our setup, very few of these prompt engineering “tips” actually improved performance.
Conclusion
Financial sentiment analysis has come a long way since 2007. Tetlock[5] began with a simple method to analyse sentiment, and today we have much more sophisticated yet equally simple to use tools such as ChatGPT. A baseline ChatGPT prompt outperforms the financial dictionary baseline by 17 F1 points, with further prompt engineering increasing the outperformance to 24 F1 points. Both improvements are extremely impressive, with the latter result showing the importance of prompt engineering (and the non-trivial nature of how this benefit from prompt engineering can be achieved).
One might thus be justified in asking, have we reached the point where we don’t need experts who can create specialised machine learning financial sentiment models? Not quite. It turns out that if we train a specialised model, specifically tailored to the task of financial targeted sentiment analysis (a process known as finetuning[25]), we can substantially outperform the best prompt and achieve an F1-score of 0.89.
Figure 3. Evaluating performance

Source: Man AHL.
Does an expert produce a stronger model than what can be achieved via prompt engineering? Yes. However, ChatGPT offers a solid and easy to use baseline, much stronger than word-counting methods. But beware the prompt engineering folk wisdom: as we sought to demonstrate, if not applied carefully, these intended improvements can induce unwanted biases and backfire.
For a comprehensive overview of the evolution and latest advancements in Generative AI models, as well as their economic impact and applications in asset management, authored by Martin Luk, click here.
Bibliography
[1] Brown T., et al. “Language models are few-shot learners.” Advances in neural information processing systems 33. 2020: 1877-1901.
[2] OpenAI (2023). “GPT-4 Technical Report.” [2303.08774] GPT-4 Technical Report (arxiv.org) [Accessed 31 August 2023]
[3] Marinov S. “Natural Language Processing in Finance: Shakespeare Without the Monkeys.” https://www.man.com/maninstitute/shakespeare-without-themonkeys. [Accessed 31 August 2023]
[4] W.K. Chan S, W.C. Chong M. “Sentiment analysis in financial texts.” Decision Support Systems. 2017; 94: 53-64.
[5] Tetlock P.C. “Giving Content to Investor Sentiment: The Role of Media in the Stock Market.The Journal of Finance. 2007; 62(3): 1139-1168.
[6] Loughran T., McDonald B. “When is a Liability not a Liability? Textual Analysis, Dictionaries, and 10-Ks.”The Journal of Finance. 2007; 62(3): 1139-1168.
[7] Alammar J. “The Illustrated Transformer.” http://jalammar.github.io/illustratedtransformer/.[Accessed 31 August 2023]
[8] Vaswani A., et al. “Attention is All you Need.”Advances in Neural Information Processing Systems 30. 2017: 5998-6008.
[9] Devlin J., et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” 2019. https://doi.org/10.48550/arXiv.1810.04805.
[10] Thoppilan R., et al. “LaMDA: Language Models for Dialog Applications.” 2022. https://doi.org/10.48550/arXiv.2201.08239.
[11] Chowdhery A., et al. “PaLM: Scaling Language Modeling with Pathways.” 2022. https://doi.org/10.48550/arXiv.2204.02311.
[12] Anthropic. “Introducing Claude.” Anthropic \ Introducing Claude. [Accessed 31 August 2023]
[13] Hoffmann, Jordan, et al. “Training compute-optimal large language models.” arXiv preprint arXiv:2203.15556 (2022).
[14] Touvron H., et al. “LLaMA: Open and Efficient Foundation Language Models.” 2023. https://doi.org/10.48550/arXiv.2302.13971.
[15] Wu, Shijie, et al. “BloombergGPT: A large language model for finance.” arXiv preprint arXiv:2303.17564 (2023).
[16] Ouyang L., et al. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems 35. 2022.
[17] Fatouros G., et al. “Transforming Sentiment Analysis in the Financial Domain with ChatGPT.” 2023. https://doi.org/10.48550/arXiv.2308.07935.
[18] Shung P.K. “Accuracy, Precision, Recall or F1?” https://towardsdatascience. com/accuracy-precision-recall-or-f1-331fb37c5cb9. [Accessed 31 August 2023]
[19] Bernard Marr & Co. “ChatGPT: What Are Hallucainations And Why Are They A Problem For AI Systems.” ChatGPT: What Are Hallucinations And Why Are They A Problem For AI Systems | Bernard Marr. [Accessed 31st August 2023]
[20] CheeKean. “The Power of Prompt Engineering: Building Your Own Personal Assistant.” The Power of Prompt Engineering: Building Your Own Personal Assistant | by CheeKean | Artificial Intelligence in Plain English. [Accessed 31st August 2023]
[21] Foy P. “Prompt Engineering: Advanced Techniques.” https://www.mlq.ai/promptengineering-advanced-techniques/. [Accessed 31st August 2023]
[22] W. Jules. et al. “A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT.” 2023. https://doi.org/10.48550/arXiv.2302.11382.
[23] Turpin M., et al. “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting.” 2023. https://doi.org/10.48550/arXiv.2305.04388.
[24] Wang X., et al. “Self-Consistency Improves Chain of Thought Reasoning in Language Models.” ICLR 2023 (to appear). 2023.
[25] Dive into Deep Learning. “14.2. Fine-Tuning.” 14.2. Fine-Tuning — Dive into Deep Learning 1.0.3 documentation (d2l.ai) [Accessed 31st August 2023]
1. In our research, we also tried extending the LM dictionary by adding phrases to it such as ‘high margin’ and assigning the appropriate sentiments – this was able to achieve an F1-score of 0.65 on the test data.
2. It also underscores the highly nuanced nature of language which may lead to disagreement among experienced and knowledgeable annotators.
You are now leaving Man Group’s website
You are leaving Man Group’s website and entering a third-party website that is not controlled, maintained, or monitored by Man Group. Man Group is not responsible for the content or availability of the third-party website. By leaving Man Group’s website, you will be subject to the third-party website’s terms, policies and/or notices, including those related to privacy and security, as applicable.