This interview originally appeared as the chapter ‘Humans versus Machines’ in the 2019 Mercer publication Investment Wisdom for the Digital Age. Dr Anthony Ledford was interviewed by Dr Harry Liem, Director of Strategic Research and Head of Capital Markets for Mercer in the Pacific Region.
Introduction
Whilst artificial intelligence (‘AI’) has been around since at least the 1950s, interest in the topic has boomed since 2012. This has been driven largely by applied breakthroughs with Deep Learning in diverse applications such as image recognition, natural language processing (‘NLP’) and superhuman performance in the game of Go. Unlike the AI doom-mongers, however, we remain sanguine about the possibility of AI ‘taking over’ as evil robot overlords, rating this as science fiction rather than impending science fact.
The experience of Man AHL over the last decade is that AI, and in particular machine learning (‘ML’), can play beneficial roles within investment management, especially in applications where there is a relative abundance of data. For example, our research and development in faster speed (e.g. daily and intra-day) systematic investment strategies, together with algorithms for trade execution and smart order-routing, have all made extensive use of ML. More recently, we have developed and deployed systematic investment strategies that exploit text-based data using NLP.
The investment management and AI industries are both undergoing rapid change. We expect to see more consolidation of investment managers as both fee erosion and the costs of doing innovative state-of-the-art research take effect. Some currently ‘cutting-edge’ alphas (including some ML models) will transition into alternative betas, whilst a new cohort of data science researchers will seek-out new alphas to replace them. Internationally, North America and China have been the leading investors in AI and ML research. The traditional model of methodological AI research being undertaken in universities has changed significantly over the last decade, with much now originating in blue-sky company laboratories and being openly published, with a corresponding drift of research staff from universities to these laboratories. Without a strong source of people to replace these university researchers, the research landscape could become fundamentally changed. To mitigate this, joint industry-university collaborations such as the Oxford-Man Institute (‘OMI’) may become more common.
What do you define as artificial intelligence, machine learning and deep learning, noting that not all of our readers may have sat through your instructional videos?
Although the terms Artificial Intelligence and Machine Learning are often used interchangeably, they mean quite different things. AI is a broad catch-all term that describes the ability of a machine – usually a computer system – to act in a way that imitates intelligent human behaviour.
In contrast, ML is the study of the algorithms and methods that enable computers to solve specific tasks without being explicitly instructed how to solve these tasks, instead doing so by identifying persistent relevant patterns within observed data.1
Deep Learning refers to a subset of ML algorithms that make use of large arrays of Artificial Neural Networks (‘ANNs’).2
Figure 1. The Relationship Between Artificial Intelligence, Machine Learning and Deep Learning
Source: MindMajix3 For illustrative purposes.
So why the resurging interest in artificial intelligence, given the field has been around since the 1950s?4
Many practical problems that humans take for granted – such as driving a car, translating between languages or recognising faces in photos – have proven to be too complex to solve with explicitly codified computer programs. Indeed, AI researchers tried this approach for decades, but empirical research showed it is much easier to solve such problems by gathering a large number of examples (so called training data) and letting the relevant statistical regularities emerge from within these. For solving such problems, this ML approach has beaten – by a wide margin – the best human engineered solutions.
Deep Learning has become extremely popular since 2012, when a deep learning system for image recognition beat competing systems based on other technologies by a significant margin, but the development of ANNs can be traced back to at least the 1940s and 1950s, as you point out.
Can you go over the concepts behind the different ML methods?
Supervised Learning is when each example in the training data has both input features (things you can observe, measure or infer) and an outcome or target. The idea is to learn the relationship between the inputs and the outcomes from the assembled training data.
For example, in the 2012 image recognition competition that kick-started all the subsequent deep learning interest, supervised learning was used on Imagenet. This is a large database of digital images where each image has been pre-labelled according to its contents (e.g. bird, fish, plant, etc).5 Here, the inputs were the images, the outcomes or targets were the key words describing each image, and the learning task was to develop a system to reproduce the labels for each image.
Unsupervised Learning refers to when the elements of the training data do not have outcomes, and the focus is then on identifying structure within the training data. One example is identifying sub-groups or clusters that exhibit similar features or behaviour, although unsupervised learning includes broader applications than just clustering.
To illustrate, referring back to the Imagenet database, if the labels describing the images are ignored, then grouping the images into separate clusters containing similar features is an unsupervised learning problem. You’d like to allocate images of birds into the same cluster, and images of fish into another, but without the labels describing the image contents you can’t explicitly assess whether an image is classified correctly or incorrectly, and consequently you can’t guide, or supervise, the learning process to do well. The task here becomes looking for common features within the images and clustering according to these.
Reinforcement Learning is a special type of ML where an agent explores an environment sequentially by taking actions that generate rewards. In many cases the reward associated with a particular action may be unclear, and all we can say is that a good or bad outcome was later obtained. Good outcomes generate positive rewards, and bad outcomes negative rewards (punishments). The idea is to maximise long-run total reward by combining exploration of the environment with exploitation of knowledge about the observed rewards.
It’s worth noting that ML systems are not necessarily bound to just one of these fields. In particular, the combination of deep learning and reinforcement learning in Deep Reinforcement Learning has produced some high-profile successes, a recent example being the AlphaGo engine which beat the world Go champion Lee Sedol.6
Figure 2. Illustration of a Deep Neural Network Structure for Image/Object Recognition
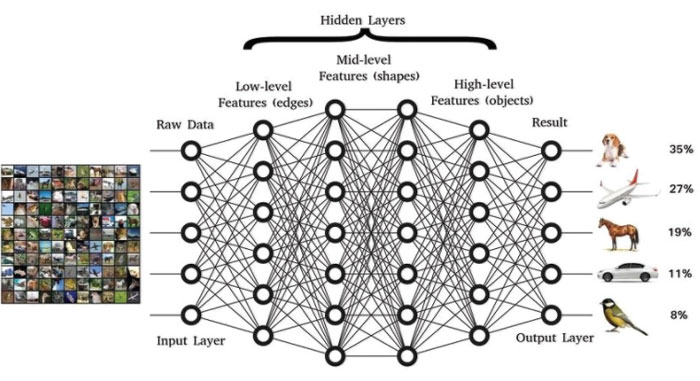
For illustrative purposes.
Modern Deep Learning systems for computer vision may have 20 or more layers. Source: https://www.researchgate.net/figure/A-typical-DNN-structure-for-image-object-recognition_fig1_324700732
There is this whole focus on ‘big data’. Why now (apart from the fact that there is a lot of available data now and storage capacity has increased exponentially)?
What do we exactly mean when we say big data?
Unfortunately there is no widely accepted definition, but in our view, big data is not just ‘having a lot of data’. It’s more about having data from multiple sources, of various types, and arising at different frequencies, e.g. information from financial markets, national statistics and news, in numerical and text formats, obtained in real-time, daily and monthly.
The more data/variables in any equation, the greater the chance of overfitting the conclusions?
Yes, it is important to contrast the unknowns within the model, which are sometimes called parameters, from the training data; in fact, it is useful to think of the training data as ‘the knowns outside the model’. Fitting any ML model involves calibrating the unknowns within the model using the information conveyed by the knowns outside the model.7
When a model with few parameters is fitted to a set of training data, then the amount of information per parameter is large compared to a model with many parameters applied to that same data. This is why simple models with few parameters can be reliably calibrated more easily than ML models which may have thousands or even millions of parameters. To address this issue, special techniques have been developed and are now in common use to assist fitting ML models.8
How do AI researchers prioritise the data?
This very much depends on the nature of the AI research: methodology breakthroughs typically involve demonstrating best-against-peers performance on one or more benchmark datasets9. As algorithms obtain ever better performance on these fixed benchmark datasets, it is legitimate to ask how effectively they will perform in real-world data applications. If they don’t generalise well outside their training data, this is another example of over-fitting. In contrast, applied research often starts with a data problem, and ideally an open mind about what tools to employ to solve it. There is no point in using a complicated ML model if what it discovers could just as effectively be captured using a linear regression.
The lesson is always to fit a simple model first, and then only adopt a more complicated ML model if the extra predictive accuracy (value) it provides is worth it. Give me the simplest model that does the job every time.
How do researchers deal with the fact that big data may contain a lot of fake data?
By ‘fake’ data, I assume you mean ‘data created with the deliberate intention of misinforming’, as opposed to statistically ‘noisy’ datasets which may contain errors, missing values or other corruptions.
For ‘noisy’ data, a suite of modelling techniques that goes by the name Bayesian Machine Learning is particularly robust at dealing with the statistical uncertainty implicit with such noise. Indeed this is one of the areas where we have enjoyed both collaborations with academics at the Oxford-Man Institute and applications within our systematic trading. Systematic fund managers like ourselves have been dealing with noisy data for decades, so in some sense this can be thought of as business-as-usual but using the latest cutting-edge tools. Other branches of ML do not naturally take account of such statistical noise, and in their basic form may fail to give appropriate results when exposed to noisy data. Such models are described as brittle rather than robust. This is a criticism often levelled against Deep Learning, however recent methodological breakthroughs in Bayesian Deep Learning have led to new ML techniques which at least partially address such issues.
Back to ‘fake’ data. This is not so relevant for market quantities such as price or volume, as there are mechanisms in place to ensure such data accurately reflect reality. It becomes more of an issue for text based data such as news or commentary, but again most financial news reporting is of a high standard. It is also the case that opinions can be wrong without being fake. It’s more of a problem in unregulated data sources such as social media, but most institutional level investment and trading is not driven by these anyway.
Figure 3. Noisy Data

Source: MNIST, Man AHL.
For illustrative purposes. The white characters on black background in the left-hand panel show handwritten digits from the MNIST database, which is a standard benchmark dataset used in image analysis. Although the writing styles are different from character to character, there is no ambiguity about the data (white) and background (black): the data are not statistically noisy, and the challenge is one of interpreting (sometimes sloppy) handwriting. In contrast, the data in the right-hand panel are statistically noisy: the signal is barely discernible against the background noise.
How do researchers deal with biases in big data?
‘Bias’ in data is an issue, and distinct from ‘fake’ or ‘noisy’ data. We all know the story of the AI-based recruiting tool that exhibited a strong gender preference in the candidates it put forward for interview because it had been trained on data with a gender bias. This deeply problematic outcome reflects an obvious, but important, truth: these algorithms learn whatever pattern is in the data they are trained on regardless of whether that pattern is what you want them to learn. Indeed removing bias in training data and developing techniques for steering ML algorithms to learn some things but ignore others (e.g. things you already know, or that stocks tend to increase in price over time) is a key task in the applied research the ML team at our firm undertakes.
How do researchers deal with non-stationarity (big data not being stable over time)?
This is a pretty universal problem in any quantitative financial modelling so is felt more widely than just in applications of ML. To calibrate any model with parameters requires data, and the more data you have, the more precisely you can estimate the parameters. Precision in estimated parameters is good to have, so this suggests you should use lots of data. However, using more data typically means using data from increasingly historical periods, but that is at the risk that these data may not reflect the current world. To avoid that risk you should therefore use only the most recent data; in other words, use few data. Unfortunately, these considerations pull you in opposite directions; it’s Catch-22. In practice, we tilt towards using as much data as we can and apply a penalty that discounts the impact of historical data compared to recent information.
Figure 4. Non-Stationarity Data

Source: MNIST, Man AHL. For illustrative purposes. Although the handwriting in the top-panel varies from character to character, all contributors adhere to the usual orientation convention for the character ‘3’. In financial data, there may be no such conventions, and relationships may change through time e.g. the correlation between bond and stock price movements has been both consistently positive and consistently negative over different historical periods.
One of the common fears about machines (and ML perhaps) is about algorithms working things out for themselves and becoming aware. Alan Turing10 once famously remarked “Machines take me by surprise with great frequency”, which suggests even in his time algorithms had some ability to create solutions (or algorithms) not designed by their creator. How far do you think we are from ‘aware’ machines?
I have been regularly surprised by algorithms since the days of my PhD deep in the last century! But… that has never meant they’re about to take over the world!
Fitting a model typically relies on some optimisation algorithm. This seeks to find a set of parameters that makes some goodness-of-fit criterion as large (or small) as it can. Sometimes, the optimisation algorithm zooms in on parameters which are useless but happen to yield particularly good values of this criterion. It boils down to the computer doing what you asked it to rather than what you wanted it to do, an annoying type of user error that I seem to repeat regularly.
Algorithms becoming aware and ‘taking over’ is definitely in the domain of science fiction rather than science fact! That does not mean algorithms can’t or won’t exhibit destructive behaviour; however if they do, then it won’t be because they’ve gained consciousness, but more likely that they’ve stumbled on some corner-case solution of an ill-specified optimisation criterion.
Which areas of investment management have the most potential to be affected by ML? For example, data analysis, stock selection, asset allocation, risk premia, electronic trading, hedge funds or other?
For ML to have an impact, you need a few things: ample amounts of representative data, and effects that are not easily described using simpler models. Without large amounts of data, you cannot precisely calibrate an ML model; you need that data to be representative so that the model learns effects that are still current, and you are just undertaking needless and pointless complications if you use a ML model when a simpler model will do. For numerical data this points towards the non-linear effects which are most prevalent at daily, intra-day and faster speeds, and where there is a relative abundance of data compared to slower strategies. Developing trade execution and smart order-routing algorithms is another ideal domain for the use of ML, and is an active area of research within our firm.
Another area where ML is having significant impact is in exploiting text-based data, using so called
Natural Language Processing 'NLP’). Although our firm and other systematic traders have been around for several decades, it is only relatively recently that such data sources have been systematically harvested and deployed within live trading.
Where do you see the main risks and opportunities for institutional investors?
The investment opportunities offered by ML strategies can be summarised in one word: diversification. As with the rest of quantitative investment, there are many more words for the risks.
Like anyone considering investing in a quantitative strategy, investors should have a good understanding of the range of market-data regimes used to build and test the model. Are the returns offered by the ML model sufficiently diversifying to their existing portfolio, or can they be adequately captured by a simpler technique? What can be expected when markets become strained, is there any reason to believe the diversification (assuming it exists) will persist? Lots of firms are exploring ML, so is the risk of crowding higher or lower for ML models than for mainstream quantitative strategies? If they have higher turnover, then what capacity do such strategies have? Should I expect them to have shorter half-lives? How much do transaction costs have to increase in order to cancel-out the alpha? Does the strategy make profits smoothly through time or in bursts? Etc.
How high do you rate the chance of large corporations with extremely deep pockets, like Alphabet, etc, getting involved in developing ML applications for investment purposes and competing with other investors?11
It would not surprise me. In fact, it is somewhat of a surprise that it has not happened already!
A partial explanation might be the large proportion of ML researchers who want to work on applications involving computer vision, self-driving cars, consumer apps and seemingly anything other than finance.
In one sense, it would be great to see the coupling of ML and quantitative finance become more mainstream. This is something Man Group has been promoting since 2007 through our co-creation of the Oxford-Man Institute of Quantitative Finance with the University of Oxford, and our ongoing financial support of the OMI’s research.
Sure, there would be more competition, but there would also be a lot more research getting done and a lot more people doing it. The trick would be to remain at the forefront of that increased research activity, something we’ve been good at so far.
I wanted to draw your attention to a Man AHL paper written in Dec 2016 called
'Man vs. Machine: Comparing Discretionary and Systematic Hedge Fund Performance' which suggests discretionary macro managers underperform systematic macro managers, even after adjusting for volatility and factor exposures over the measured time period. How do you think this debate will shift with the advent of ML?
From my experience, ML strategies have the most to offer towards the faster end of the spectrum of strategies deployed by most systematic macro managers. Furthermore, not all systematic macro managers will make use of such strategies.
So the impact on performance at the group-wide level of systematic macro managers is likely to be modest, at most.
Do you have any thoughts on the increased competition among quantitative managers?
Increased competition is likely to mean that only managers offering genuinely differentiated alpha (arising from ML or other novel sources) will be able to resist fee erosion. This is clearly a much wider issue than just relating to ML.
What in your opinion distinguishes a good from a mediocre quant manager?
I have quite a few criteria!
- An independent risk management team that monitors for the build-up of inadvertent portfolio exposures;
- A wide range of diversifying strategies so that undue reliance is not placed on any one strategy or concentrated group of strategies;
- A joined-up understanding of strategy design, portfolio construction, trade execution and risk;
- A long track record of trading through a wide range of market environments;
- A stable, international, multi-disciplined and diverse team with low turnover that contains both new recruits and old-timers (like me!);
- State-of-the art computing hardware and software;
- Active engagement with the outside world e.g. through academic collaborations and publications;
- Contributing to rather than just taking from the open-source community;
- An open culture where staff collaborate rather than operate in silos;
- A test-trading program where the latest research ideas can be verified in live trading without risking client capital;
And finally, an honest research culture where nobody seeks to hide research that does not work, or to pretend it does!
How do you decide when a model no longer works?
It’s rare in our style of trading for a model to suddenly stop working, and many models are kept fresh through periodic refits. Sometimes the components of a model are superseded by new models, and in that case they get turned-off.
More generally the amount of trading capital a model obtains in the portfolio will be driven by its long-term risk-adjusted return and correlation with other models. This means that a model which consistently underperforms or fails to diversify will naturally receive a diminishing allocation as time progresses, although obviously this de-allocation occurs with some lag.
If the structural assumptions underpinning a model fundamentally change (e.g. a currency peg is implemented or relaxed) then turning-off the model in that market is merited.
What do you think is the best investment time horizon to apply ML? How important is real-time data?
Within our suite of trading models, ML has the highest representation at the faster end, with holding periods extending from intra-day out to multiple days.
Faster signals than that certainly exhibit greater non-linear structure, however such effects are hard to capture as alpha in the client-scale funds typical of large systematic managers like us. In a nutshell, they are just too fast. However, when applied in trade execution, such effects may offer significant advantage in reducing transaction costs, e.g. enabling orders to be front- or back-loaded depending on the short-term predictability of the limit-order book. Real-time data is essential for that.
Are there any other important developments in the quantitative space worth noting?
There is a good deal of research effort being deployed on modelling text and other alternative data sources, and the range of instruments being traded continues to extend. These are just the latest pieces in the industry’s ongoing hunt for diversification through new models, new markets and new trading horizons. ML and big data fit somewhere as pieces in that hunt.
Can you comment on some of the other interesting areas apart from ML that the Man-Oxford Institute is currently working on?12
Within the University of Oxford, the Engineering Science Department’s hub for ML houses both the OMI and the broader Machine Learning Research Group (‘MLRG’). Research activities span a diverse range of topics with applications ranging from astronomy to zoology, with examples including detecting disease-bearing mosquitoes, identifying exoplanets from data gathered using NASA’s Kepler space telescope, systems for remote fault detection and monitoring, and making energy networks and storage more efficient.
Research in the MLRG also addresses the broader societal consequences of ML and robotics, e.g. their impact on employment. Alongside the OMI’s strong research focus on ML and data-centric methods for finance, its members, associate members and graduate students undertake a broad range of interdisciplinary and collaborative projects, e.g. assessing the impact of regulation – and breaches of regulation – on markets, and investigating the relationship between future earnings and the language used in corporate announcements.
On a side note, do you think there is a premium for illiquidity?
My experience would suggest there is, however it is hard to disentangle this from the inverse premium associated with a market’s ease of access. In particular, I have seen the same algorithms trade in easily accessed liquid markets and hard-to-access illiquid markets and do much better in the latter. But I should add that this has been against a backdrop of non-standard central bank, regulator and government measures , which typically have more impacted the liquid easily accessed markets.
Will that continue? Who knows.
Also, if you look across the industry, the half-life of trading strategies tends to be monotonic with their time horizons. Slower strategies typically last longer, but with lower Sharpe ratios, than higher frequency strategies.
As a scientist, do you have any thoughts on the premium for sustainability?
My colleagues in Man Numeric have spent almost two years unpacking Environmental, Social and Governance (‘ESG’) data, conditioning for statistical biases and removing exposures to other factors, and thereby have obtained something meaningful and orthogonal. This is the closest thing I have seen to an ESG or sustainability factor. Of course, it is quite possible that as more people focus on ESG and sustainability that a premium may emerge – it is a changing environment where ESG and non-ESG activities could become advantaged or disadvantaged by policy.
How do you see the investment industry evolving over the coming decade?
At the industry level, I expect to see more consolidation as both fee erosion and the costs of doing innovative state-of-the-art research take effect.
Closer to home, some currently ‘cutting-edge’ alphas (including some ML models) will transition into alternative betas, whilst a new cohort of data science researchers will seek-out new alphas to replace them. Discretionary managers will make extensive use of data dashboards that deliver assimilated big data views.
Run-of-the-mill computer hardware (and whatever the smartphone has become in a decade’s time) will make today’s state-of-the-art systems look just as ridiculous as those from 2009 do today.
Who will have the edge in leading the AI research of the future? Apart from yourself, are there certain leading academics, corporations or even countries that you could identify?
Internationally, North America and China have been the leading investors in AI and ML research for some time, with Europe, Australasia and the rest of the world now trying to compete, if somewhat belatedly.
I’d expect how this funding landscape evolves to be the deciding factor in the shape of AI developments over the next decade. That said, the traditional model of methodological AI research being undertaken in universities has changed significantly over the last 10 years, with a lot more now originating in blue-sky company laboratories and being openly published, with a corresponding drift of staff from universities to these laboratories.
Without a strong source of people to replace these university researchers, the research landscape could become fundamentally changed. To mitigate this, joint industry-university collaborations such as the OMI may become more common, enabling academics to operate effectively in both camps, rather than exclusively in one or the other.
Final question: investing: art, science or skill?
All three. But it’s rare to find all these in the same person at the same time, which is why we believe in teams.
1. This general definition of machine learning is very broad. However, within Man AHL the convention is to exclude standard statistical techniques such as linear regression. Others take a different view.
2. Artificial Neural Networks are computing systems inspired by the biological neural networks found in animal (including human) brains. Such systems progressively improve their ability to do tasks by considering examples, generally without task-specific programming.
3. https://mindmajix.com/machine-learning-vs-ai
4. The field of artificial intelligence research was founded as an academic discipline in 1956. The earliest research into thinking machines was inspired by a confluence of ideas that became prevalent in the late 1930s, 1940s, and early 1950s. Research in neurology had shown that the brain was an electrical network of neurons that fired in all-or-nothing pulses. Alan Turing's theory of computation showed that any form of computation could be described digitally. The close relationship between these ideas suggested that it might be possible to construct an electronic brain.
5. See http://www.image-net.org/
6. See https://en.wikipedia.org/wiki/AlphaGo
7. As an illustrative example, the same is true for simpler statistical models such as linear regression. The unknowns within the model are the intercept and slope parameters. The knowns outside the model are the observed data, which are known in the sense that they are given, and do not change.
8. Examples include techniques such as Dropout and Early Stopping, both of which are used to avoid overfitting in Deep Learning applications.
9. For example, Imagenet.
10. Alan Turing (1912 – 1954) was an English mathematician, computer scientist, logician, cryptanalyst, philosopher and theoretical biologist. In 1941, Turing and his fellow cryptanalysts set up a system for decrypting German Enigma signals. Turing is widely considered to be the father of theoretical computer science and artificial intelligence. "Computing Machinery and Intelligence" published in 1950 is considered the seminal work on the topic of artificial intelligence.
11. https://deepmind.com/about/, https://ai.google/research/teams/brain
12. http://www.oxford-man.ox.ac.uk/Areas-of-research
13. In response to the Global Financial Crisis.
You are now leaving Man Group’s website
You are leaving Man Group’s website and entering a third-party website that is not controlled, maintained, or monitored by Man Group. Man Group is not responsible for the content or availability of the third-party website. By leaving Man Group’s website, you will be subject to the third-party website’s terms, policies and/or notices, including those related to privacy and security, as applicable.