Introduction
It is crucial for our foreign exchange execution system to run with low latency, due to the quote-based nature of FX trading. Banks stream quotes to us, which we then compare in order to select the most favourable price at which to trade. It is therefore important that the quotes are received real-time. Furthermore, favourable quotes can disappear quickly, so we need to act fast to avoid unwanted rejections.
Execution / Trading systems typically consist of multiple services that each handle a different process and communicate with each other via Inter-Process Communication (IPC) to complete the entire trading flow. As complexity grows, it is generally more practicable to have smaller components to isolate concerns / failures. In fact, with a micro-service architecture, it is not unusual to have hundreds of services running in a trading system. IPC therefore contributes significantly to overall system latency.
This article describes our journey adopting Aeron messaging to improve latency, thus reducing slippage.
Microbenchmarking
Microbenchmarks were conducted to understand the scale of IPC latency. It is non-trivial to harness microbenchmarks correctly, as you mustn’t negatively impact the latency yourself when making the measurement, and every nanosecond counts! Warming-up the Java Virtual Machine, conducting hotspot compilation and multi-threading activities can all add extra latency to your measurement, making it significantly less accurate. Luckily, there is a very good Java library, JMH, available. Most of the figures described in this section are the result of JMH benchmarks.
Firstly, let’s look at the cost of passing data between two threads using the popular ping pong benchmark. As shown in the code below, two Java threads communicate via a pair of volatile longs with constant polling.

The round trip latency is around 0.1 μs (micro-seconds). Interestingly, light travels about 100 feet in the same period of time. However if we use a blocking collection, SynchronousQueue, instead of volatile long, the latency will jump to 100+ μs, more than 1000 times slower! This demonstrates how costly context switching as a result of synchronization across threads can be.
In the real world, we would like to send more than a single long. If we use ConcurrentLinkedQueue and send messages of 100 bytes, the round trip takes about 0.3 μs.
Expanding to IPC, Aeron and Chronicle-Queue are two well-known ultra-low latency solutions for IPC within the same box. Both leverage shared memory and achieve 0.25 μs round trip latency with a 100 byte message, which is impressive as it is faster than using ConcurrentLinkedQueue between two threads in the same process!
For communication over the network, we need to use a reliable protocol, i.e. TCP is regarded as reliable while raw UDP is not. There are many messaging systems running on top of TCP. Their round-trip latency is in the range of at least tens of milliseconds as bound by TCP protocol. Aeron and Tibco provide a reliable protocol on top of UDP for improved performance. The round-trip latency of Aeron is about 10 μs, while Tibco’s is around 200 μs.
As described above, Aeron demonstrated superior performance in low latency benchmarks both for communicating on the same box and for communicating over a network. Moreover, we found that its latency did not deteriorate under increased load. It can saturate pretty much any transport it runs over. This is illustrated by the following result of rpc-bench:
Figure1: Ping-pong benchmark
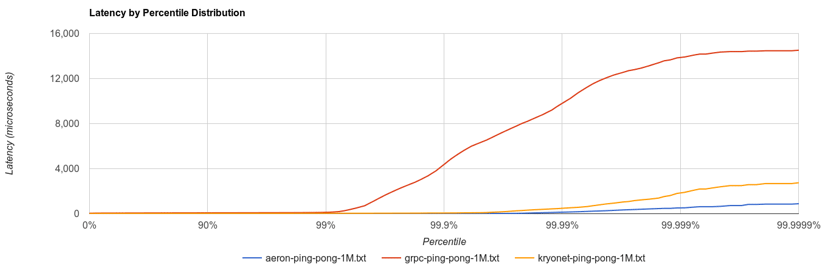
Figure 2: Heavy load benchmark
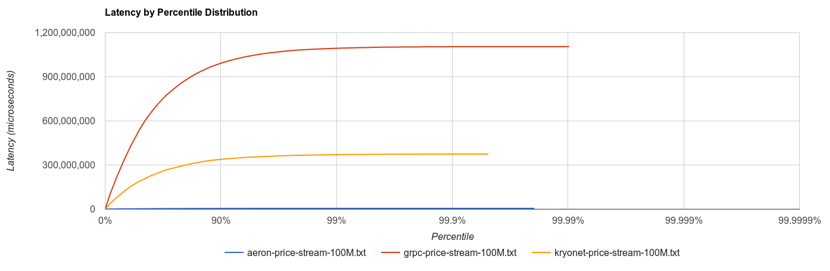
The latency of Aeron stayed low until the 99.999% percentile in the Figure 1: ping pong benchmark, and had no noticeable latency increase under heavy batch load as shown in the Figure 2. In comparison, the latency of grpc/http2 and kryonet deteriorated significantly in both cases. That means that Aeron is much more resilient to spikes of messages and is able to recover quickly when a large number of messages have to be processed in one go to catch up.
Further considerations in adopting Aeron
Encouraged by Aeron’s ultra-low and predicable latency, we built an IPC simulation environment, emulating our execution system, to test Aeron under various loads over a few weeks. Better latency statistics, by at least an order of magnitude, were recorded at every percentile when compared to the previous implementation. The improvement became even more noticeable as the message rate increased - up to 2 orders of magnitude under the very heaviest load.
Low latency is not the only reason to adopt Aeron:
- Aeron is an open source product with many proven usages, such as akka remote;
- Aeron’s design principles are sound. It is GC-free (using off-heap memory), lock-free and leverages non-blocking IO, no exceptions on the message path, and uses a single writer whenever possible. We are inspired by these principles and apply them in building our own execution systems;
- Aeron’s archive and cluster provide the main functionalities we are looking for to build a fully fault-tolerant message layer. The Aeron messaging layer allows us to split the system into critical trading and reporting processes without worrying about adding latency into the procedure. While trading processes strive to be fast and stable, the reporting processes are less speed-constrained and so present different engineering challenges. With this architecture, we also build resiliency into the system so reporting processes cannot interfere with our trading activity.
Result
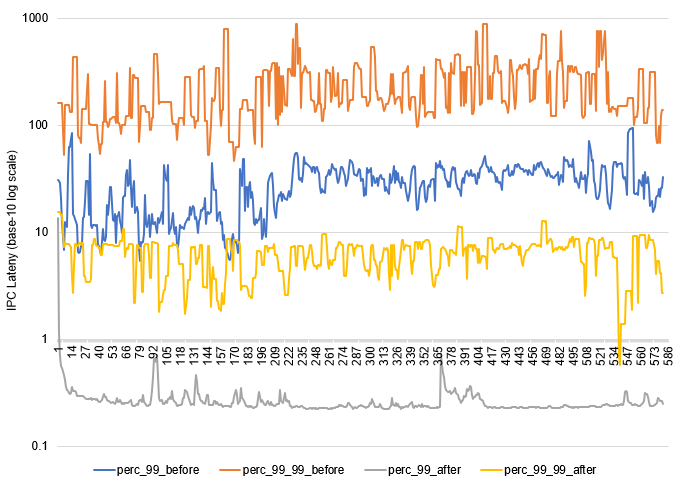
We switched IPC to use Aeron at the beginning of 2019. It has been running smoothly without issue ever since. Along with system updates and other performance tuning, the IPC latency has reduced by at least an order of magnitude at every percentile. The following diagram compares the 99-percentile and 99.99-percentile latency before and after switching and shows the 50 times reduction of 99.99-percentile latency. Note that the after latency is much more stable, therefore more predictable, too.
You are now leaving Man Group’s website
You are leaving Man Group’s website and entering a third-party website that is not controlled, maintained, or monitored by Man Group. Man Group is not responsible for the content or availability of the third-party website. By leaving Man Group’s website, you will be subject to the third-party website’s terms, policies and/or notices, including those related to privacy and security, as applicable.