For single-core CPU performance, Moore's Law (which states that the number of transistors in new integrated circuits will double around every two years) isn’t quite as true as it once was. Whilst the law has kept consistent, single-core CPU performance has stagnated over recent years, and whilst it is still trending upwards, the improvement has slowed considerably.
The common assumption is that new technology is a necessity required to keep up with the market and competitors. Companies tend to replace their hardware after around three years, and the industry is therefore geared towards performing hardware refreshes on a 3–5-year cycle. This has led to a glut of three-year-old hardware available at a significant discount compared to newer options.
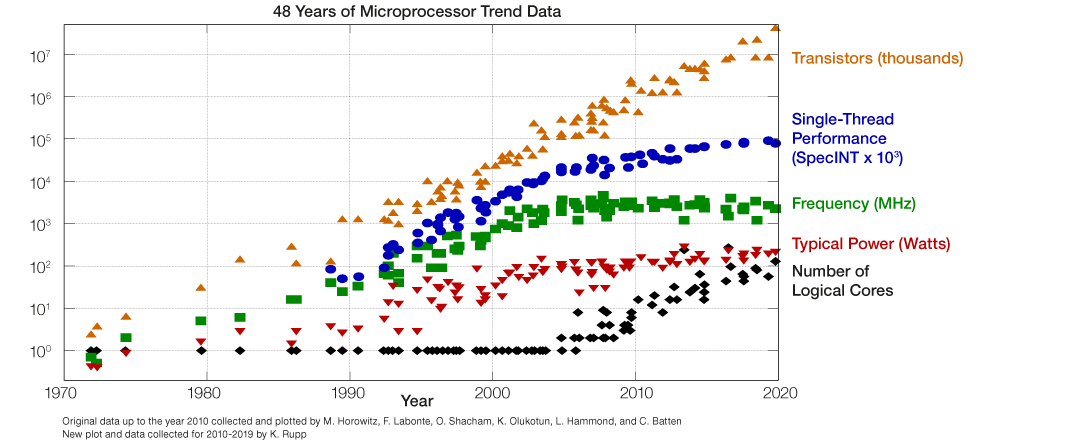
Back in the day, when Moore's law was still in full swing, CPU performance tracked transistor count, and it made perfect sense to replace hardware every two to five years. However, our own internal benchmarking shows that for real life workloads, a current compute core is only about 1.6 times faster than a comparatively ancient CPU from 9 years ago. Sure, newer CPUs have many more cores, but given that older hardware can often be procured at a large discount, it makes complete economic sense to buy used hardware over shiny, new, and expensive stuff.
In true hedge fund style, we took advantage of this market inefficiency and built our own internal cloud on top of used hardware. Through this, we achieved more than four times the computational power a traditional approach would have netted – and, as a nice bonus, this ‘digital recycling’ creates a much better return for the environment.
Re-using hardware is environmentally friendly
There is an enormous, constant waste-stream of servers and components flowing from around the world to economies in Asia and Africa, where they are dismantled and recycled, often using procedures that are both damaging to the environment and unsafe for the people working within the recycling business. By using existing servers for longer, we can reduce the amount of electronic waste sent for recycling (safe or unsafe), in turn reducing the toxic materials entering the environment. This also reduces the energy consumption and CO2 emissions inevitably caused by building new servers.
Using a CO2 estimation tool to calculate the combined emissions from manufacturing and power usage of servers, we found that the break-even point for new servers versus refurbishing servers is seven years. This is, we think you’ll agree, a very long time in terms of technology. Furthermore, this number assumes 100% utilization - with lower utilization levels, the break-even point moves even further out!
The Solution: Hybrid Cloud
Why did we build our own cloud? Frankly, it saves enormous amounts of money over solely using a cloud vendor, and purchasing used hardware makes the cost/benefit calculations even better. Running an internal cloud would have been much more challenging years ago, but Kubernetes, Spark, Terraform, and a myriad of other open-source technologies make cloud technology easy to stand up, and easier still to automate. They even deal with hardware failures gracefully (Yes, even your shiny new server with ‘redundant-everything’ can - and will - fail).
This article explains why we run our own internal cloud and compute resources at Man Group. We define what we mean by cloud, and present a case-study which explains why we bought cheap and unreliable hardware to run our Spark compute jobs - and why you probably should too.
What is a cloud anyway?
Back in the day, an internet adage proclaimed that "the cloud is just someone else's computer". This is flippantly true, but it also misses a lot of detail about why cloud has become popular.
For a new start-up looking to run public facing services, there are immediate benefits to deploying these to a cloud, for example:
- Cheap launch costs: there are no data centres to build, no servers to buy, no storage to procure, and networking is already provided;
- Fast start-up: cloud infrastructure is much faster to start using than traditional DC builds
- Scaling infrastructure up and down on an as-needed basis (perhaps even throughout the day);
- Experimentation is cheap, easy to monitor, and fast to set up.
There is also lots of tooling for programmatically building clouds. These technologies enable users to define exactly what their cloud should look like by, in effect, writing source code. The configuration is usually stored in some version control store (e.g. git). This gives a complete history of all changes made, and as the state is stored and well defined, configuration drift (e.g. size or count of servers, network rules etc) can be quickly found and reverted.
One might at this point wonder why all companies are not rushing to move all their workloads to the cloud, and one of the reasons is that as a project or company grows, the hosting costs in the cloud can become very expensive indeed, to the point that it is cheaper to take the overhead hit of provisioning your own data centre, storage, network, etc. The cloud is, after all, just "someone else's computer", and the costs associated with running large scale infrastructure are still there, and they will still have to be paid by the customer. Our calculations show that for long-running processes that use a lot of computer resources (be that CPU, RAM or fast storage), these costs quickly become prohibitive.
Another issue facing some organizations is the question of where your data resides. Ideally for simulation purposes, the data needs to reside "close to the compute" from a latency perspective. If all data is already in the cloud, that's probably acceptable, but what if you have data that is used and generated internally, or that can't be moved to the cloud for data regulation reasons?
Man Group's cloud journey
The Man Group cloud and cluster journey is a story of three parts. Broadly, we have the following types of workloads:
- Containerized workloads, which we are currently migrating to run in Kubernetes;
- Long-running general purpose virtual servers (for example Linux desktops for users, servers that run some trading strategies, development servers etc.);
- Spark / Hadoop compute type workloads for research projects.
Containerization
We adopted Docker as our containerization solution back in 2015. At the time, we were running almost exclusively on physical servers. Applications were installed with hand-crafted install scripts onto specific servers. Using Docker to package software up into distinct containers helped us think of applications as discrete sets of components, rather than an entangled set of binaries, libraries and data. Even though most of our workloads were still running on physical machines, we could now make the physical machines much more alike - in short, they became fungible.
If we bought this service from an external vendor, it would likely be called container-as-a-service (or ‘CAAS’ for short).
Virtualization
We run both VMWare and OpenStack for virtual machines. Most of our internal development and research workloads are on OpenStack, with production on VMware. This is our infrastructure-as-a-Service (or ‘IAAS’) offering to our users. Typical workloads in this "cloud" consist of long-lived machines serving Linux desktops or Jenkins slaves.
In the beginning, we used to provision servers by running complex commands on a command line, but the environment quickly grew in both size and complexity, and maintaining it became an exercise in patience. To overcome some of the maintenance difficulties, we began using a tool called Terraform from HashiCorp. Terraform allows us to write code-like configuration, which - amongst other functionality - defines what our virtual machines should look like. Once the configuration is written, we run the Terraform tool to build the environment.
One (of many) benefits of running Terraform is that our VMware virtual machines are built in an almost identical way to our OpenStack machines, so there is less mental overhead when building machines in one environment compared to the other.
A typical workflow is that one of our SREs makes a configuration change in our codebase, which is then reviewed by a team member, and once approved automatically applied to the environment. This provides a well-documented environment (the documentation is the code itself), as well as auditing and visibility for other team members. Some of our users even self-serve configuration changes using the same method, which gives them a faster turn-around time for requests, as well as alleviating workload for the infrastructure teams.
Spark / Hadoop workloads
Our third form of cloud-like offering is a sizeable Apache Spark cluster, mainly aimed towards research purposes. Spark lets our users write massively parallel jobs and utilize far more memory and CPU resources than could fit into a single machine.
The Spark setup consists of a master node and a set of workers, where bits of work are scheduled. The master handles hardware/software failure on nodes by rescheduling bits of work on other nodes, making it fairly fault-tolerant. In the sections below, we go through our requirements for the Spark servers, and why we made the choices we did.
Why we built our own cloud(s)
At Man Group, we do utilise external clouds – and they do offer many benefits. For our use cases, however, they do not always represent the ideal case scenario, which is why we have moved towards a hybrid cloud system using infrastructure on-premises.
In the case of running general-purpose machines, external cloud works after a fashion (and we do have many machines already running at one of the big cloud providers), but when it comes to Linux desktops the latency is just not good enough for many of our users.
Our workloads also suffer from data-locality issues. That is, we need fast access to shared data stores (using NFS and S3), and particularly NFS has been quite difficult to get fast enough access to in public cloud. Compounding the issue, our workloads typically make many small reads/writes to shared storage as well.
Case-study: Spark nodes
Our internal clouds are growing at a markedly rapid pace as it is easy and fast to provision resources in them. Earlier in 2021 we expanded our OpenStack and Kubernetes clusters significantly. In the future, we aim to expand our Spark capacity as and when necessary.
Beware the performance benchmarks
When evaluating solutions, it is obviously vital to be able to m easure and rank the performance of the solutions. There are benchmarks on the internet for all conceivable CPUs, and it is easy to compare the figures in the benchmarks and then draw conclusions about the relative performance of servers.
We were very keen to understand the real-world performance of different processor configurations with our workloads. To do this we ran one of our representative trading strategies within a Docker container using a fixed set of test data. We measured how long the simulation took to complete and ran the benchmark many times using Hyperfine, resulting in an average runtime of our real-world scenario.
We tried to come up with a reasonable variety of options to test, so that we could find the sweet spot of performance over cost. As our Docker test suite let us generate benchmarks with relatively little human input, this was essentially a background task once the machines had been built and configured.
The options we benchmarked were:
| ID | Threads | RAM | CPU Year |
Description |
|---|---|---|---|---|
| DL360-g10 | 72 (Xeon Gold 6240 @ 2.6GHz | 768Gb | 2020-q1 | 1U server |
| DL325 | 32 (AMD Epyc @ 3.0GHz) | 256Gb | 2019-q3 | 1U server |
| DL380-g9 | 24 (Xeon E5-2643 @3.4GHz) | 1024Gb | 2016-q1 | 2U server |
| DL380-g9-2 | 24 (Xeon E5-2620 @ 2.4GHz) | 768Gb | 2014-q3 | 2U server |
| BL2x220c | 24 (Xeon X5660 @ 2.80GHz) | 96Gb | 2010-q1 | Baseline legacy blades |
The CPU Year column denotes when the CPU was first available to purchase, not necessarily when the server was bought.
Run times for the benchmark container:
| ID | Average runtime (in seconds) | release-date |
|---|---|---|
| BL2x220c | 27905 | 2010-q1 |
| DL380-g9-2 | 23834 | 2014-q3 |
| DL380-g9 | 22258 | 2016-q1 |
| DL325 | 20414 | 2019-q3 |
| DL360-g10 | 17479 | 2020-q1 |
Unsurprisingly, the newer the hardware, the faster our benchmark finishes. However, it is surprising that the newest hardware, with a CPU 10 years newer than the oldest CPU in the test, is only about a third faster! Shown on a graph, we can clearly see that the newer CPUs to the right are faster, but the graph really brings home how little improvement per core there is in our real-world scenario over the last 10 years.
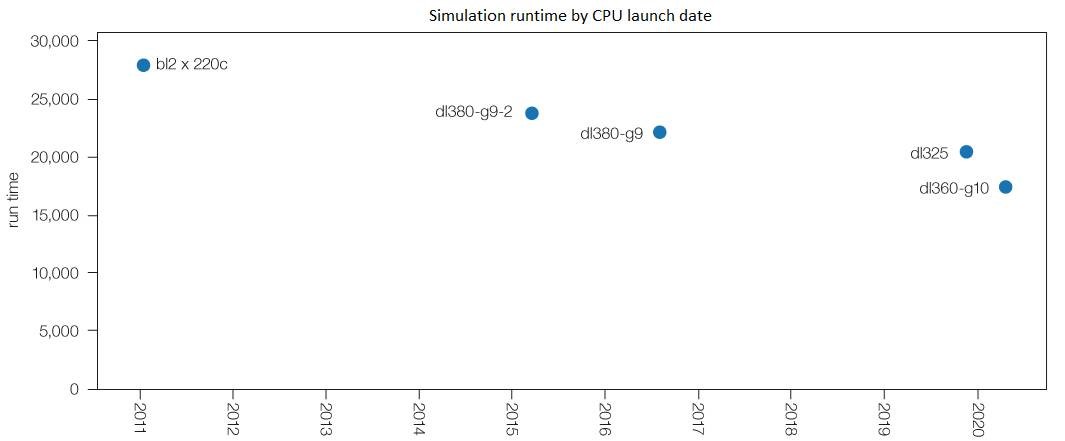
To take into account that the individual cores do get slightly faster over time, we calculate a core-improvement factor for each type of CPU. For example, a DL360-g10 CPU core performs about 60% more work per unit of time compared to that of the old processor in the BL2x220c, so the core-multiplier for the newer CPU is 1.6.
Newer CPUs typically have a higher core count than the older ones, so to represent how much work a single CPU of a particular type can perform we also multiply the core-multiplier by the number of cores. This gives us a real-world number to use for comparisons.
Aside: Why external cloud was dropped
The initial feeling of the team was that we should move all workloads to an external cloud, because it "made sense". However, once we investigated what our jobs actually look like, and what the cost implications were, we quickly changed our mind. We picked a representative job from our Spark cluster, and found the following statistics:
- The job ran for 72 hours in total across all cores, utilizing a staggering 11,948h of compute time (1.36 years);
- At the time of the benchmark, an Amazon cloud (AWS) r5.large instance (2 cores, 16Gb of RAM) cost $0.0346/hour (London spot pricing);
- Assuming roughly the same performance from the on-prem job and AWS, the job would cost 11948h * $0.0346/h = $413 using an r5.large instance.
Given that our cluster was saturated, in order to replace it with an AWS cluster of the same size, we would need to purchase significant external cloud capacity. Running our Spark cluster jobs externally would therefore cost us millions annually – equivalent to a significant annual hardware investment, but with far more limitation.
That is; if we moved to AWS, we would need to pay a premium per year to maintain our existing performance, without any expansion. The conclusion must be that it is currently not cost-effective for us to run Spark in public cloud.
Hardware choices
We reached out to our suppliers and got some quotes for different hardware. A subset of our options is presented in the tables below. All servers are HP based (DL360, DL325 or blades), so we only list the CPU threads per one machine in the table below:
| New / refurb |
chassis | CPU | threads/server | adjusted threads/server |
RAM/server |
|---|---|---|---|---|---|
| New | DL360 | 2x Intel Xeon Gold 6240R | 96 | 153.6 | 768Gb |
| New | DL360 | 2x AMD Epyc 7542 | 128 | 204.8 | 1Tb |
| New | Apollo 2k | 1x AMD Epyc 7542 | 64 | 86.4 | 512Gb |
| Refurb | BL460c | 2x Intel E6-2659v2 | 48 | 67.6 | 384Gb |
When viewed as a scatter plot, the DL360 server with Epyc processors looks like a real powerhouse!
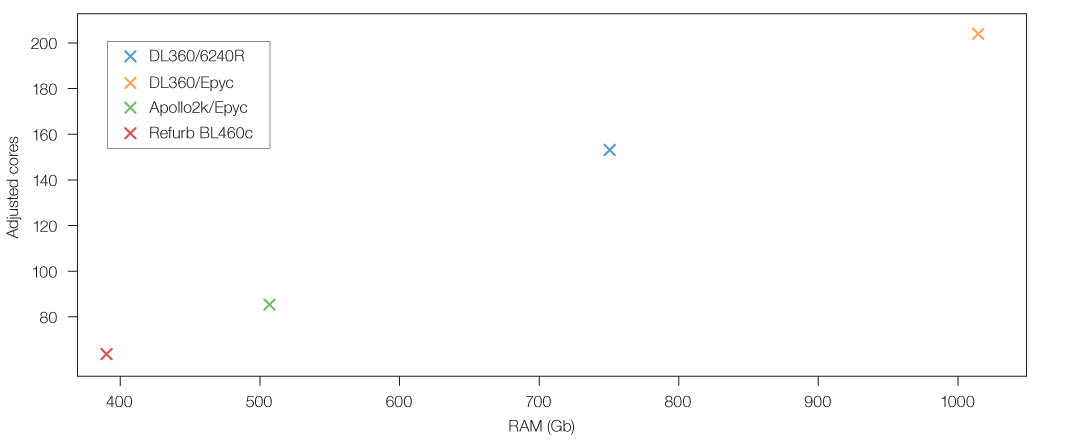
If we had unlimited funds, we would be purchasing DL360 servers with the AMD Epyc processor, but that isn’t the best value for money. The table below shows “Budget Adjusted Threads” and “Budget Adjusted RAM”. The extreme outlier in value terms is the BL460 refurbished hardware option.
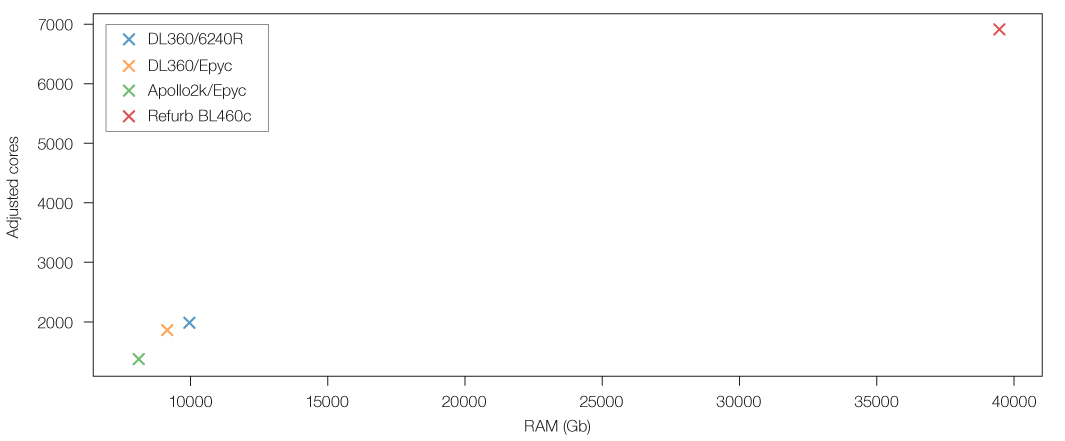
| chassis / CPU | # budget adjusted threads | # budget adjusted RAM |
|---|---|---|
| DL360 / Intel Xeon Gold 6240R | 1997 | 10.0Tb |
| DL360 / AMD Epyc 7542 | 1843 | 9.2Tb |
| Apollo 2k / AMD Epyc 7542 | 1381 | 8.1Tb |
| BL460c / Intel E6-2659v2 | 6912 | 39.5Tb |
When plotted, we can immediately see the incredible value the humble refurbished hardware offers compared to new hardware.
The Results of our Setup
Given the vast difference in compute power and RAM achievable with our budget, it is very difficult to ignore the value that refurbished hardware offers, and this is indeed the option we went for.
Yes, the hardware is older. Yes, we must use more network ports than we would with the other solutions (This was included as part of the server cost). Yes, it uses somewhat more power, though less than expected - our measurements show that the DL360 option uses 1.65 times the power of the refurbished BL460c option to achieve 2.27 times as much compute.
The RAM utilization graph shows the difference in allocated RAM in the cluster before and after the introduction of the new compute nodes (introduction of the new nodes happened in the middle of the graph).
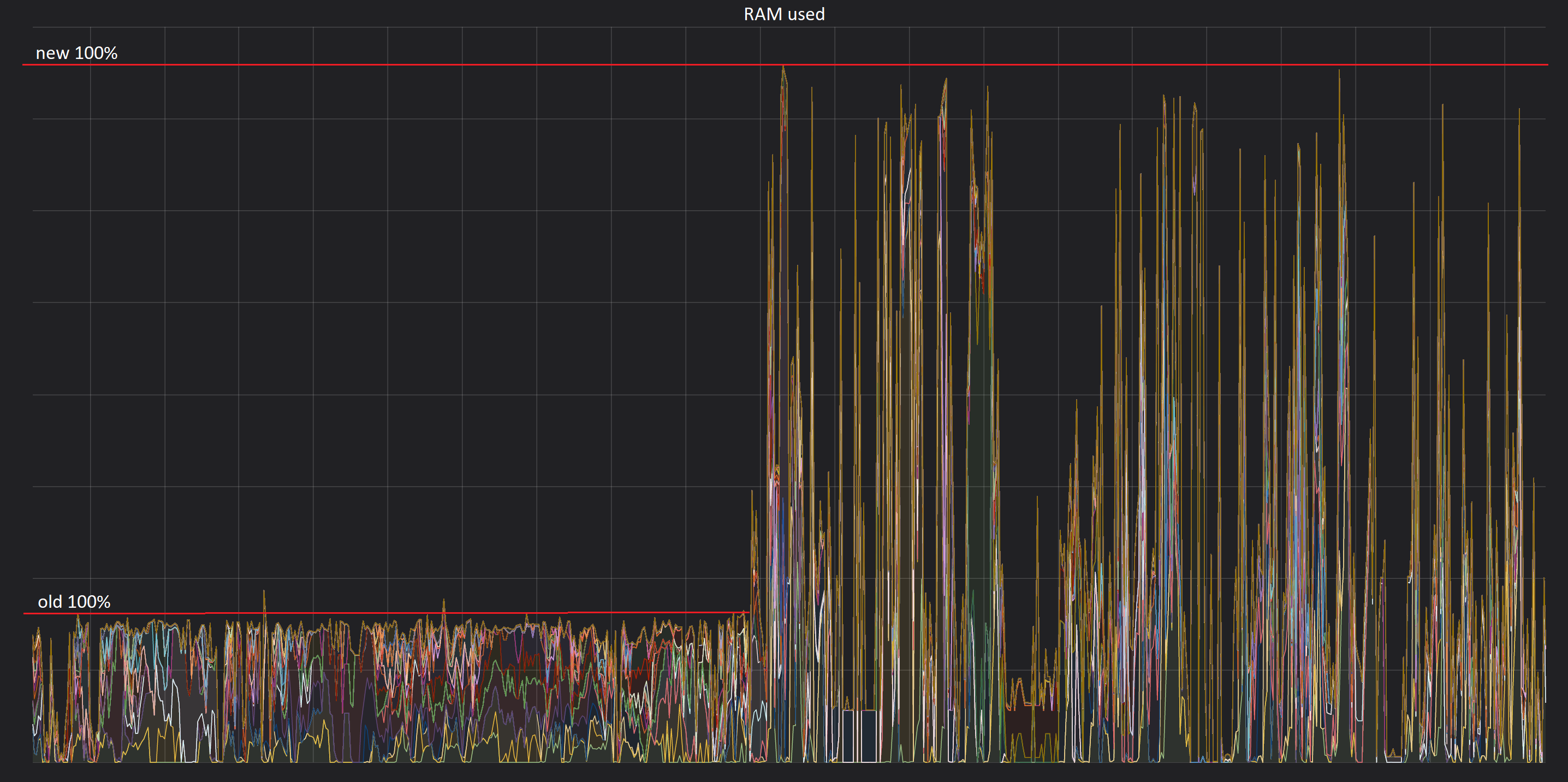
Before the upgrade, the cluster was always 100% utilized in terms of RAM, but afterwards there is spare capacity, although we expect that over time this spare capacity will also be used. It is counter-intuitive, but that is exactly the situation we want to achieve - if the RAM is 100% used, but without lots of queuing jobs, then we are using our hardware effectively.
There is no question that buying used hardware is problematic in terms of absolute reliability of the hardware. All hardware eventually fails, but the failures seem to happen either almost immediately when new, or after many years of constant use. The hardware we are using is still well within the ‘sweet spot’ of reliability, but even so we project that around 20% of the BL460c servers will fail within the three years we intend to keep them. In a normal setting, this may be an issue, but if the servers are treated as pure compute nodes, where Spark manages the rescheduling of failed computations, there really is no need to worry. We intend to track the process improvements and price-to-performance ratio of the blades over time, periodically replacing them with newer recycled blades as required.
One common worry about buying a multitude of servers is how to provision the operating system and environment on them. We can rebuild all our Spark servers automatically in less than a day, which means that we can easily scale our estate with more servers when the need arises. To achieve this, we use two open-source products:
- Cobbler to provision the operating system on the servers over the network;
- Ansible to perform OS configuration and Spark setup.
Conclusion
By using refurbished hardware, we were able to purchase four times as much RAM, and 3.5 times as many performance adjusted CPU cores, compared to what new hardware would have cost.
Spark and Kubernetes enable us to, in effect, not worry about hardware reliability, and to use all our hardware at very high efficiency (RAM at close to 100%, CPU at above 50%). The automation around the build and configuration means that adding ‘new’ nodes will be a low-cost operation, freeing up infrastructure team members and saving time overall.
Whilst there are some challenges in this approach, we believe that the effort was well spent – not only for the improved hardware capacity, but for the environment as well.
You are now leaving Man Group’s website
You are leaving Man Group’s website and entering a third-party website that is not controlled, maintained, or monitored by Man Group. Man Group is not responsible for the content or availability of the third-party website. By leaving Man Group’s website, you will be subject to the third-party website’s terms, policies and/or notices, including those related to privacy and security, as applicable.