At Man AHL, we use Python for almost everything. We build models in Python, support trading systems in Python, and write web visualisation tools in Python.
At Man AHL, we use Python for almost everything. We build models in Python, support trading systems in Python, and write web visualisation tools in Python.
September 2017
Why Python?
A common question we get is: why Python? Isn’t it too slow? How do you scale it to the size of your team? How do you ensure your software is robust?
A Lingua Franca
The biggest strength of Python is that everyone can use it.
We have carefully reviewed, thoroughly tested production code that’s widely used in live trading. We also have scrappy experiments, one-off scripts that are thrown away after being run. Python is great for both scenarios.
Previously, research on models would be done in R, and the model would be rewritten in Java for production. This presented a number of challenges:
- The rewrite increased the time taken to take a model to production.
- If the model isn’t behaving as expected, was the bug introduced by the Java translation, or did it exist in the R prototype?
- If a bug is found in the Java version, is the bugfix applied to the R version too?
- How can we run experiments on our R prototype and be confident that the Java implementation will behave the same way?
By using Python everywhere, we facilitate communication between teams. Anyone can run an experiment using the same code that runs in production.
Using a single language is also great for analytics. We can dump interesting data as a production model runs, and be confident that we can analyse it from our usual research tools.
Great Interactive Tooling
ipython is excellent. It’s easy to load up some data and interactively examine it or plot it.
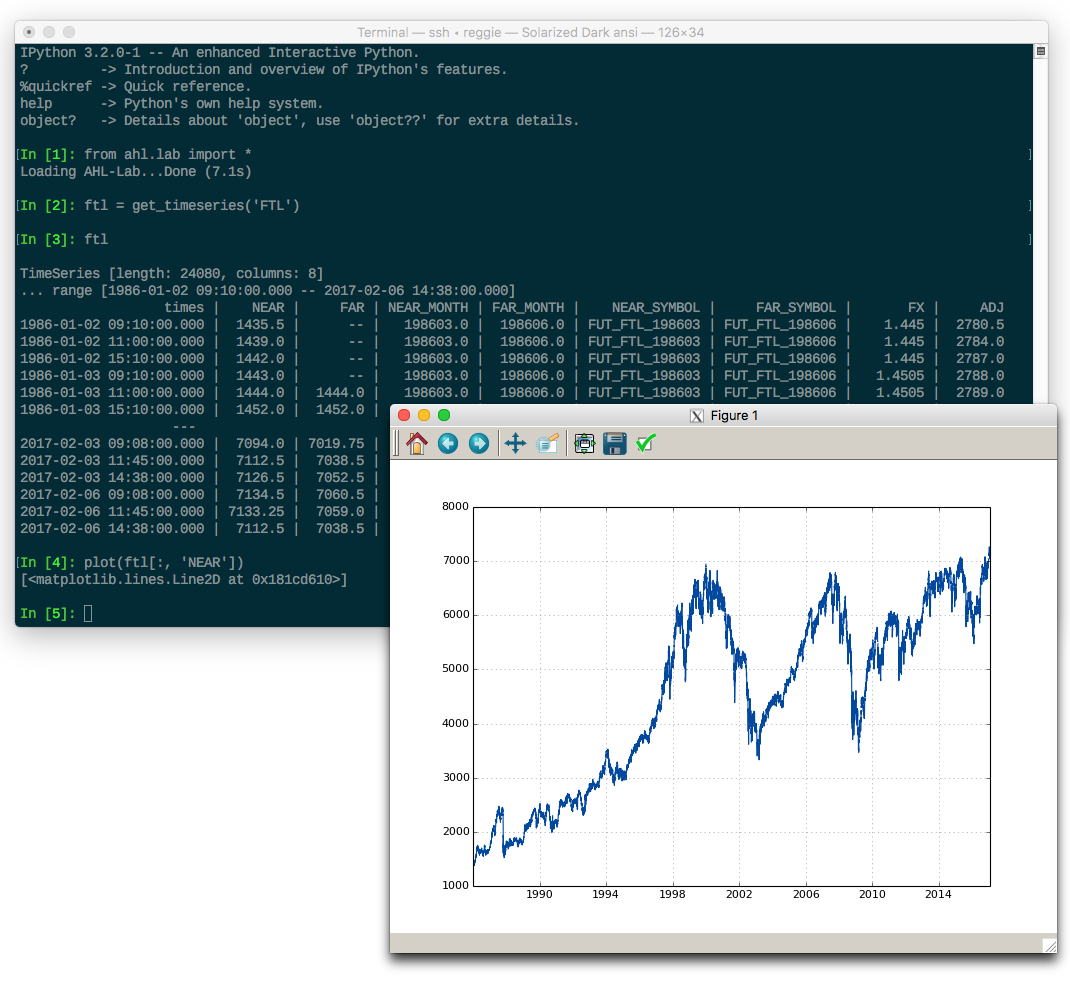
In the above screenshot, I’ve loaded up the historical price of a FTSE future and plotted the near price.
The dynamic nature of Python is great for this. You can run snippets of code without needing to write a full program. We even support running model simulations from within the Python shell.
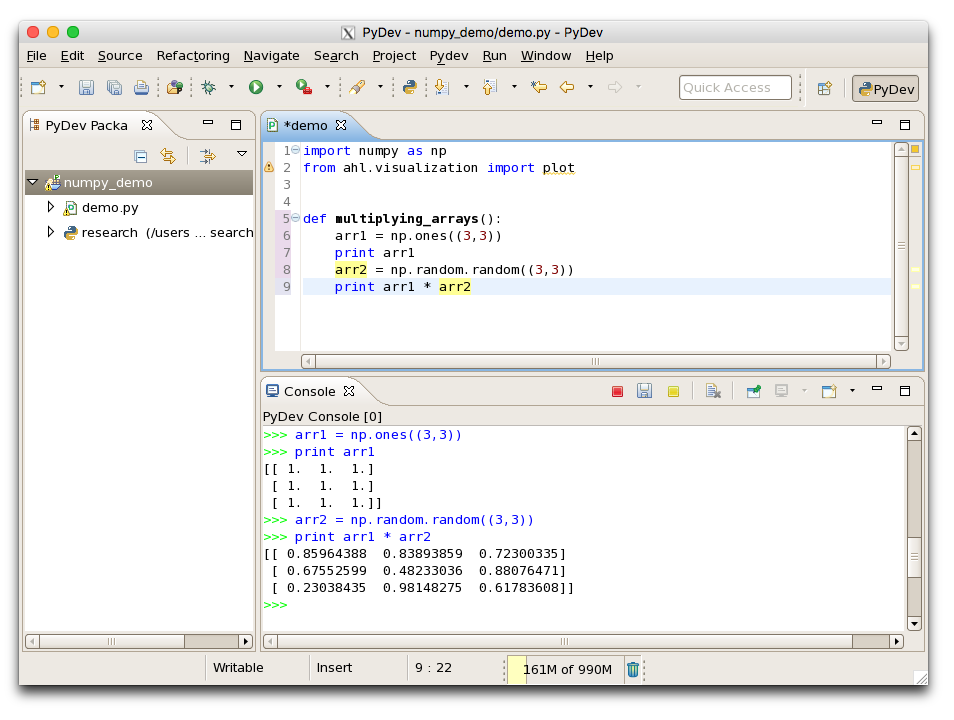
We find interactive development so useful that we’ve customised PyDev (relevant pull request) to let you run snippets of Python from your current program.
In the above screenshot, you can see that I’ve run individual lines inside a function definition, allowing me to develop functions incrementally.
Fast Enough
We’re not a high-frequency shop, but we do deal with non-trivial amounts of data.
For example, consider a model using one year of one-minute price history. With 64-bit floats, that’s over 4 GiB for each market.
To deal with this volume of data, we use numpy extensively. Numpy gives you C-style arrays of floating point arrays, with C-level memory usage (efficient, contiguous numbers in memory).
If you can express your computation in terms of numpy operations, you can even get C-like performance from your Python code!
Of course, sometimes that’s still too slow. If you’re implementing computationally expensive machine learning algorithms, or low-level data types, you need every last drop of performance.
We use Cython or roll our own C/C++ in these situations. Cython is great for making your code more low-level whilst still preserving the structure of the original Python implementation.
Huge Ecosystem
Python has a huge selection of libraries available, and particularly excels at numerical computing.
In addition to numpy, we use scipy, pandas, ipython, matplotlib and many other niche libraries. We’re able to contribute our bugfixes back and even share tools we’ve developed.
The quality and breadth of existing Python libraries enables us to build more robust software in shorter periods of time.
Other Languages
It’s worth mentioning that we’re not exclusively using Python. Our execution team uses Java: their code is more latency sensitive. The data team has some tooling in Go (we don’t need the ability to do interactive experiments with data ingestion).
There’s the inevitable javascript too: we have web tools to monitor model performance, and these require some javascript.
Overall, Python has been a great fit for Man AHL. It’s great for collaborating, performant, and the ecosystem is extensive.
If you’re interested in working on a Python platform used to trade 19bn USD, we’re hiring!
You are now exiting our website
Please be aware that you are now exiting the Man Group website. Links to our social media pages are provided only as a reference and courtesy to our users. Man Group has no control over such pages, does not recommend or endorse any opinions or non-Man Group related information or content of such sites and makes no warranties as to their content. Man Group assumes no liability for non Man Group related information contained in social media pages. Please note that the social media sites may have different terms of use, privacy and/or security policy from Man Group.